多元線性迴歸 multiple regression
2022-08-22
import warnings
warnings.filterwarnings("ignore")
from sklearn import datasets
data = datasets.load_boston().data
target = datasets.load_boston().target
# 下面就將資料隨機切成 data_train, data_test, target_train, target_test 這樣可以快速切 20%
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(data, target, test_size=0.2)
# print (data_train.shape) # 多少筆 每筆幾個欄位
from sklearn.linear_model import LinearRegression #匯入sklearn.linear 線性迴歸模型
regr_model = LinearRegression() #建立模型物件
regr_model.fit(data_train, target_train) #用訓練集來訓練模型
predictions = regr_model.predict(data_test)
# print (predictions.round(1)) # 印出預測值(四捨五入到小數第一位)
# print (target_test) # 印出測試集真實目標
# print (regr_model.score(data_train,target_train).round(3)) #訓練集的決定係數(四捨五入到小數第三位)
# print (regr_model.score(data_test,target_test).round(3)) #測試集的決定係數(四捨五入到小數第三位)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
print (mean_absolute_error(target_test, predictions).round(3))
print (regr_model.coef_.round(2)) # MEDV = -0.01*CRIM + 0.04* ZN + ..... + 23.64
print (regr_model.intercept_.round(2))
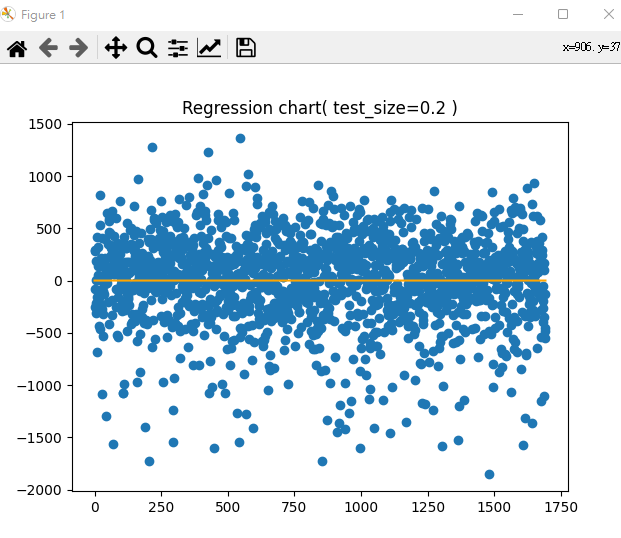
x = np.arange(predictions.size) # from 0 to 101
y = x * 0 # y = 0
plt.title('Regression chart( test_size=0.2 )')
plt.scatter(x, predictions - target_test) # 與 target_test 差多少
plt.plot(x, y, color='orange') # y = 0 線
plt.show()

import pandas as pd
df = pd.read_csv(r'https://archive.ics.uci.edu/ml/machine-learning-databases/00560/SeoulBikeData.csv', encoding = 'gbk', index_col =['Date'])
data = df.copy()
data = data[data['Functioning Day'] == 'Yes'] # 只取 Functioning Day 為 Yes
data.pop('Functioning Day') # 去 NaN
data = data.rename(columns= {'Temperature(癈)': 'Temperature(*C)', 'Dew point temperature(癈)': 'Dew point(*C)'}) # 換掉非英文標題
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['Seasons'] = le.fit_transform(data['Seasons']) # 把 Seasons 換成數字
data['Holiday'] = le.fit_transform(data['Holiday']) # 把 Holiday 換成數字
target = data.pop('Rented Bike Count') #只取Rented Bike Count 有的(把 物件Rented Bike Count丟掉傳至target)
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(data, target, test_size=0.2) #資料隨機切成 data_train, data_test, target_train, target_test 且 test_size= 20%
from sklearn.linear_model import LinearRegression
regr = LinearRegression() #建立模型物件
regr.fit(data_train, target_train) #用訓練集來訓練模型
predictions = regr.predict(data_test)
print (regr.score(data_train, target_train).round(3))
print (regr.score(data_test, target_test).round(3))
import numpy as np
import matplotlib.pyplot as plt
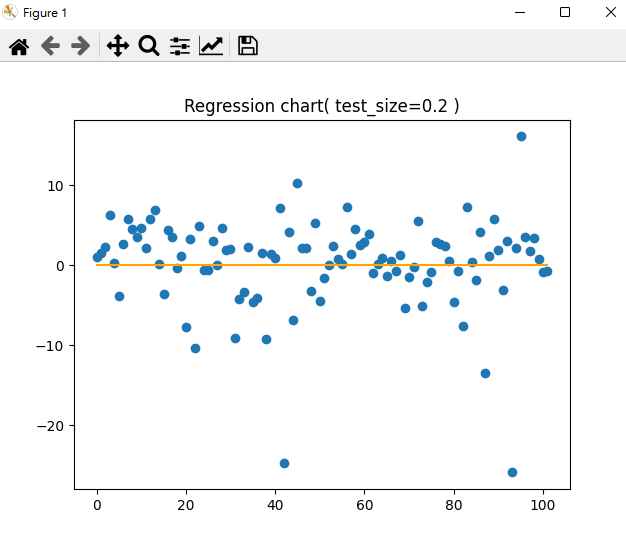
x = np.arange(predictions.size) # from 0 to n
y = x * 0 # y = 0
from sklearn.metrics import mean_absolute_error
print (mean_absolute_error(target_test, predictions).round(3))
print (regr.coef_.round(2)) # 2.8220e+01*Count + 1.8460e+01*Hour + ..... + 763.19
print (regr.intercept_.round(2))
plt.title('Regression chart( test_size=0.2 )')
plt.scatter(x, predictions - target_test) # 與 target_test 差多少
plt.plot(x, y, color='orange') # y = 0 線
plt.show()